Notes on making a Markdown parser from scratch in JS
Mar 21, 2021Check out the completed project here and the code on replit here
I really wanted to understand the basics of compilers, but with all these terms like tokenizers and lexers and parsers and recursive descent and LL(1), I got really intimidated and never looked into it too much.
But the concept of a compiler is fascinating. You input some text, and using some simple logic, you can convert it into something completely different.
At the same time, I was thinking a lot about owning my stack. We have nearly ubiquitous personal computing, and yet, the moment we need a problem solved, we look to buying software- using 'free' software that just sells our data instead, or using pre-built libraries to do the job for us.
So, bringing these two together, I decided to learn about compilers by directly building something I could use.
This is by no means a definitive tutorial on how to make parsers, let alone markdown parsers. Instead, it's a log of what I learnt and how I learnt it. For a truly comprehensive look at making MD parsers, check out this website, which contains a formal explanation for how Github Flavoured MD is parsed.
TL;DR
A compiler converts content from one language to another language using a set of formal rules.
The entire process is just massaging an input to make an output trivial to compute. We're building the input into higher levels of abstraction (the tokenizer) that then makes it easy to create a tree (parser), that can then easily be converted to the output HTML.
To avoid dealing with indexes, we use a Reader abstraction that makes reading an input list (tokens or chars) easy. We can add other functions like peek() and hasNext() to make it even easier to process.
The Tokenizer uses the Reader to read the individual chars in the input and determine whether they're normal text or if they're special tokens. This is what allows it to tell that ** means bold, and not two asterisk literals, or that a # at the start of a line isn't a literal # but instead represents a header.
The Parser takes in this list of tokens and converts it into a tree. To do this, we create a function for each DOM node that could be output- h1, blockquote, p, and so on. We then use mutual recursion between these functions to consume tokens (with a global Reader object to avoid dealing with too much state) that takes in the tokens it needs and outputs a corresponding DOM node. The using mutual recursion (AKA recursive descent) the Parser builds up a tree structure.
We then can then use a pretty simple function to parse this tree into HTML.
False starts
Initially, I looked up some parser tutorials, and tried to dive into it headfirst. That was a bad idea. There were too many complicated abstractions that I didn't understand the purpose of.
There's a common mistake I make when following tutorials. I blindly copy the concepts and code shown, without understanding why they exist. But until you understand exactly why it's done the way it is, have you really learnt anything? Or have you just learnt to mimic properly?
I didn't fully understand why we needed a Reader abstraction that read tokens one by one. I didn't get how recursive descent parsing really worked, only that we had to involve recursion somehow. I didn't get why we needed to split a tokenization and parsing step.
And so, I scrapped following tutorials, and decided to look at it from scratch. If I had to solve the problem myself, how would I do it?
Do stuff, see if it works, iterate.
While reading tutorials, I found a quote from this post that really struck a chord. There's a whole section about enjoyment and fulfillment that serves as a mini philosophy of programming. I'd recommend reading the entire thing.
For our purposes, the most salient parts came from a paragraph about speed:
Superior programmers are simply people who iterate faster.
The best way to think about this is that a developer who works 10 times faster than the next developer is allowed to fail 10 times more frequently before releasing code into production.
The way to achieve superior speed is to access the problems as directly as possible. Each barrier between you and the problem will slow you down. Common barriers are too many tools, abstractions, build processes, compile steps, frameworks, missing documentation, unclear flow control, and so forth.
Applying this to this project means forgetting all the abstractions and tackling the problem directly with tools that I understand. And so, I programmed a super janky MD parser implementation with for loops and nested if statements.
My janky implementation and what we can learn from it
I documented building the janky implementation in this tweet thread, and the full janky implementation can be found here in my commit history, but here's some snapshots into how it went.
I broke the problem down into the very bare essentials. To start with, I tried to parse just one header.
Markdown can be essentially be broken down by line, so I used regex to convert a raw input string into a list of lines that could then be individually parsed.
Here's that initial code. This is embarrasingly bad, and I feel physically ill when reading it, but it got the job done:
output = ""
for (let [lineIdx, line] of lines.entries()) {
let inputIdx = 0
let headerType = 1
//headers
if (line[inputIdx] == "#") {
if (line[inputIdx + 1] == "#") {
headerType++
if (line[inputIdx + 2] == "#") {
headerType++
}
}
output += '<h' + headerType + '>'
/*
the code below starts the loop at the index of the headerLevel,
which means it'll only accept chars after the hashtags.
E.g. h3 will skip the 0th, 1st and 2nd element to start at idx 3
*/
for (i = headerType; i < line.length; i++) {
output += line[i]
}
output += '</h' + headerType + '>'
}
}

I slowly expanded the functionality into blockquotes, lists, paragraphs with bold and italics, but it became clear that a janky solution required extremely janky logic.
Take the logic for anything between *s:
// if we hit a *, it's either a * or **, figure out which one
if (line[i] == "*") {
// handle if it's **
if (line[i + 1] == "*") {
// we need to skip the second *
i += 1
output += '<strong>'
// j is an index that starts after the **
let j = i + 1
while (line[j] != "*") {
output += line[j]
j++
}
output += '</strong>'
// set the global loop index to skip the ending **
i = j + 2
}
I wrote a while loop within a for loop, that used an index initialised from the index of the for loop, and when it completed, set the index of the for loop to the index that was 2 more than the index it completed at. Whew. That's a lot of crap.
Here's a snippet of the code required to check for whether we're at the end of a for list:
if (lines[lineIdx + 1]?.[0] != "-") {
output += '</ul>'
}
Again, extremely convoluted. We:
- get the next line (as an optional in case it doesn't exist)
- get the char at the 0th index
- check that it isn't "-"
As a general rule, I realised that all the places we see extremely convoluted logic could (and should) probably be abstracted away to allow for more elegant code.
And the constraints I found should probably lead to ideas and abstractions used in actual compilers.
Making a real MD compiler
So what were the issues with the janky code above?
- keeping up the index of the next char was annoying
- there were no easy ways to refer to the previous line/char without using messy code
- there was no real separation of concerns: finding out what token was present (** or * for example) was mixed in with outputting the right tags
Additionally, the code wasn't even fully functional. We couldn't parse nested lists and we couldn't have italics within bold text, for example.
So to fix this, we can come up with some abstractions.
| Problem | Solution |
|---|---|
| keeping the index of the next char | a Reader abstraction |
| refer to the previous line/char elegantly | a Reader abstraction |
| separation of concerns | Split the code into a tokenizer and a parser |
The Reader
Keeping the index of the next char, referring to the previous one, seeing if chars are left - these are all issues related to reading the input in various ways.
To fix all of them, we can create a Reader abstraction. At its simplest, it keeps track of the index, and returns the next value in a sequence.
We can also add functions like peek(), which allow us to check what the next token is without incrementing, and some other helper functions related to reading a sequence of tokens, like hasNext(), readUntil(), or others depending on your approach.
We can initialize a global Reader object and increment it from within any function we use. This way, we don't have to constantly think about indexes and updating them. Any time we want to go to the next token, we just call next().
The Tokenizer
Initially, I was confused as to what the tokenizer and parser each actually did, and why we need to separate them in the first place.
The problem is this. The compiler needs to first figure out what the text it's seeing actually is. When it sees a **, is that the same as normal text, or does it signify something else? If it sees a > at the start of the line, should it treat it differently to a > in the middle?
Each of these could be called a token. A token could be just plain text we need to render, or a special symbol that signifies displaying that text in a non-standard way. So for every special character/ sequence of characters, we can define a symbol.
For example, the line this is **really cool *markdown* ** could be converted to:
['this is ', 'BOLD', 'really cool','ITALIC', 'markdown', 'ITALIC', 'BOLD']
The Parser and recursive descent
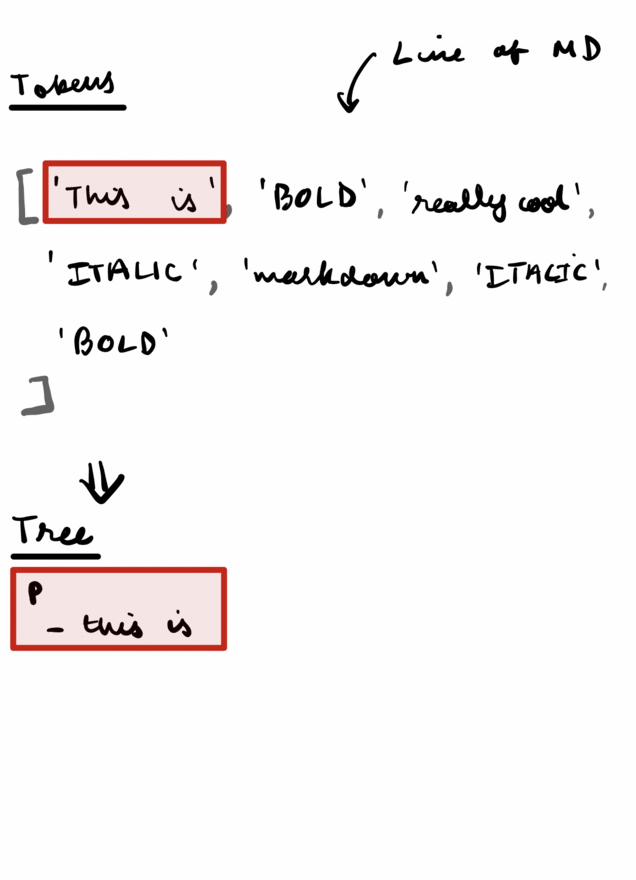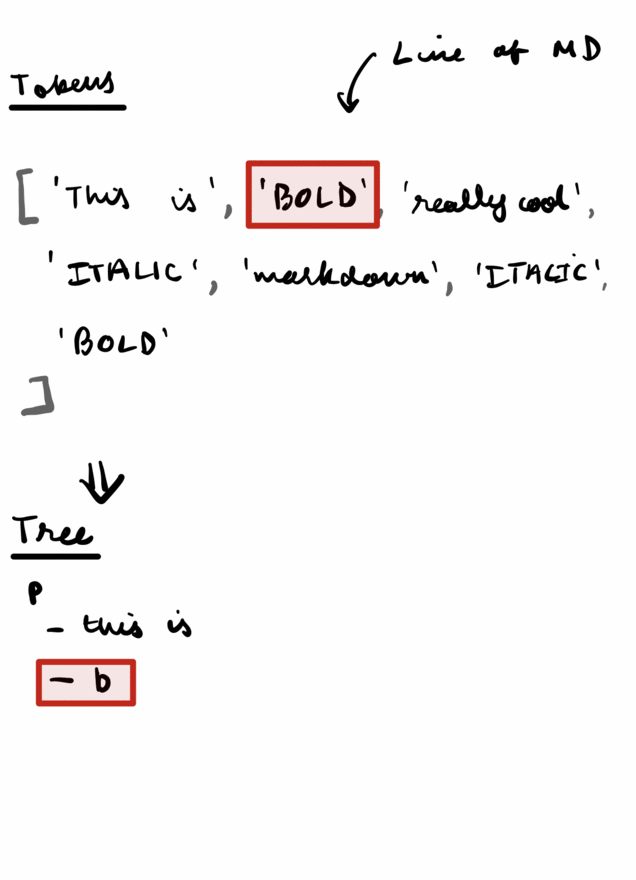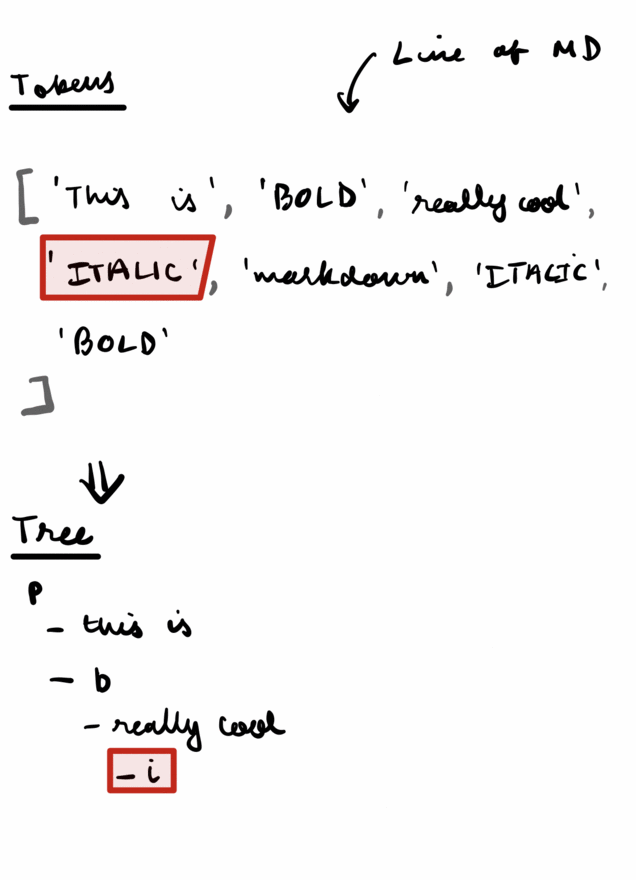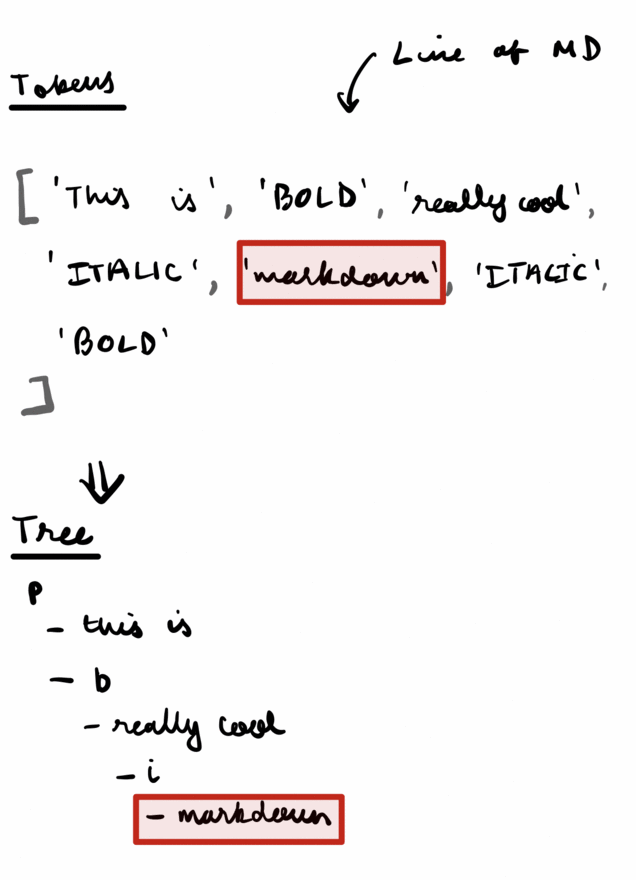
Given a list of tokens, the Parser's job is to figure out how to convert them into a tree.
Now I wasn't entirely sure at first why we need a tree as the output. Surely we could just output a sequence of html directly? The issue is that that would again require a lot of janky code.
Take the sequence of tokens above as an example. If we had an output string, we'd have to append an opening <p> tag, then this is , then a bold tag, add really cool , an italics tag, markdown, then look at our state and add a closing p tag, then based on state another closing b tag, then another closing i tag.
Storing this much state, like how many tags are left open and when we have to close them, would be unnecessarily complicated. Instead, it would make a lot more sense to break the parser down into several function that were each responsible for returning only one tag. E.g. parseHeader(), parseBold(), etc.
And this is where recursion comes in. If we had a function that just parsed text, if it hit a 'BOLD' token, it'd switch to parseBold(), if it hit an 'ITALIC' it would switch to parseItalic().
But inside bold tokens, we can expect to find an ITALIC token (nested emphasis). Which means we could call parseText() from within parseBold(), which was itself called by parseText(). I was really confused by what recursive descent meant at first, but this is all it is- mutual recursion, functions calling other functions which in return can call the original function again.
And that's why putting them into a tree makes sense. A tree is itself a recursive data structure, with each branch being a tree itself. So we could just keep calling the function for every node that needs to outputted.
So the output would look like a tree with a structure like this:
html
- p
- this is some text,
- i
and some more text that's highlighted,
- b
some that's highlighted and bold,
- b
- and some that's just bold.
- blockquote
- 2b or not 2b,
- i
- that is the question
After I generate a tree, making a function that converts it into html is simple enough.
Conclusion
Compilers always seemed like an uber-complicated concept reserved for only 10x engineers™️. But it's strange how a topic that seemed so opaque even a month ago now feels comprehensible. While I still haven't grasped a lot of it, it feels like I have a foothold to climb from. All it took was an earnest shot at making a toy version.
It's strange how everything I learnt could have seemed similarly unaccessible, except I never really stopped to consider how hard things could be. If I had known about the various complexities of programming before starting, I might never have. Instead, I just wanted to program my Arduino, and slowly grew from there.
So like Linus told me, making toy projects, even if they don't have immediate 'utility' as a hack, are probably the best way to learn about CS.
Special thanks to Linus for his advice, explanations and answers to my incessant questions.