Writer Detection With LLM Latent Space Images
26 Mar, 2024
I remember reading the introduction to Jessica Livingston’s Founders at Work and thinking how much it sounded just like Paul Graham. Only to realize it was written by him. Something about the way he writes is very distinguishable. The same can go for a piece of prose from Shakespeare, or Mishima. But what exactly is that distinguishing factor?
If humans can detect the style of some writing, that means there’s something quantifiable in there, and computers should be able to detect it too. This experiment was about seeing if I could make that happen.
Unfortunately, I have my OS class, Databases class, and Molecular Cell Biology homework to do, so the goal of this is NOT to do a super comprehensive study (I don't have the time 😔), but rather to see if this method is even feasible. Specifically, can we detect writers from just their progression through LLM latent space?
What's coming up in this post:
- yes, it seems feasible
- but I might be fooling myself
- thoughts about quantifying style (I think it's average devation from the average)
- lots of images of LLM latent space progressions
If you're doing research similar to this, or have any interesting things to share with me along these lines, please reach out! (twitter, email) Also I'm actively looking for 'research mentors', i.e. nothing too intense, just people who are willing to drop me a line of advice now and then for research related. If you are/know someone who can do this, I'd appreciate getting in touch!
Introduction/Intuitions
This was my gut feeling: someone’s style is nothing but their deviation from the average. What makes something striking is the very fact that it slightly surprises us in a specific direction. Reading PG’s intro scratched a certain part of my brain. Perhaps it’s his short sentences. Maybe it’s the terseness in the writing. Where I’d subconsciously expect the sentence to continue, he brings it around to stop.
Over a large enough piece of text, a good writer might have many patterns and idiosyncrasies. If there was a way to quantify them, and then average them out, we might have a quantifiable number or vector that represents the style of a person. In this sense, style could be the average deviation from average (with the magnitude and direction captured).
I remembered two things that led me to the core of the experiment.
An old experiment
5 years ago, I did an (abandoned) experiment to see if I could detect who was typing based on the cadence of their typing. I reasoned that there’d be some patterns with which their hands would move across the keyboard, which meant that the time between certain keys would be higher, between others lower, in a way that could be unique to a typer.
Instead of simply passing in this data as text, which might have been smart, I remember I wanted to find a more compressed signature per user. And so I wrote a program that generated an image. The keys on a keyboard were mapped to their points in space. A line was drawn for each successive key press. The longer it took between keys, the thicker the lines. The longer each keypress, the bigger the circle.
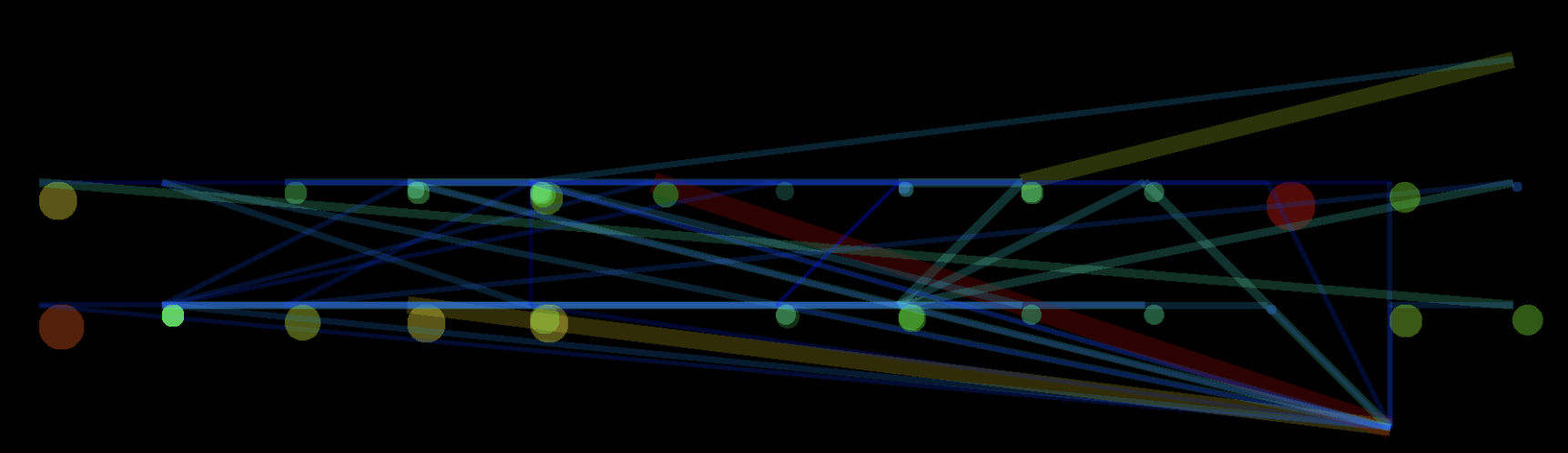
I think I moved on to something else before finding any useful results, positive or negative. But it remembered it when I saw the next point
Wolfram, Shannon, Images
In Stephen Wolfram’s explainer on ChatGPT, there’s a really interesting section where he maps out the progression of sentences through feature space. I also read Shannon’s biography where there’s a section on the walk of a drunkard:
“The classic model of a stochastic process is a drunk man stumbling down the street. He doesn’t walk in the respectably straight line that would allow us to predict his course perfectly….. But watch him for long enough and we’ll see patterns start to emerge from his stumble, patterns we could work out statistically if we cared to. Over time we’ll develop a decent estimation of the spots on the pavement he’s likely to end up” – A Mind At Play, Jimmy Soni & Rob Goodman
Could the style of a writer be the way they ‘stumble’ through feature space? And could we perhaps detect certain patterns in that stumbling? Much like my abandoned high school experiment, we could perhaps see patterns in the visualization. And with LLMs we actually have a way to visualize their path!
Method
I generate images of the progression of sentences through feature space. To do so, I:
- Loop through every word n the sentence, getting the hidden state vector of 0 to n-1 passed into the model
- Perform PCA on the features, and then use the axes with the most variance to plot the points
I used Microsoft Phi-1.5, it seemed like a pretty powerful base model
Here’s some examples of the output:
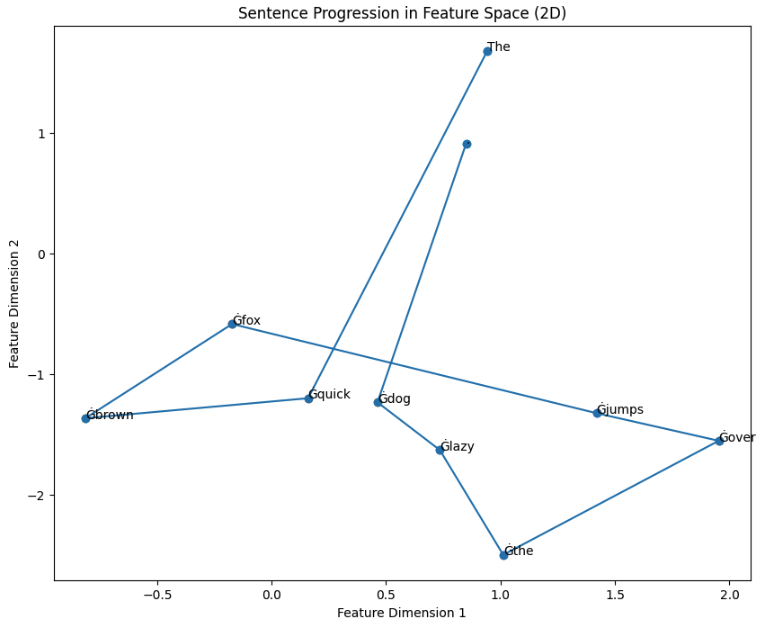
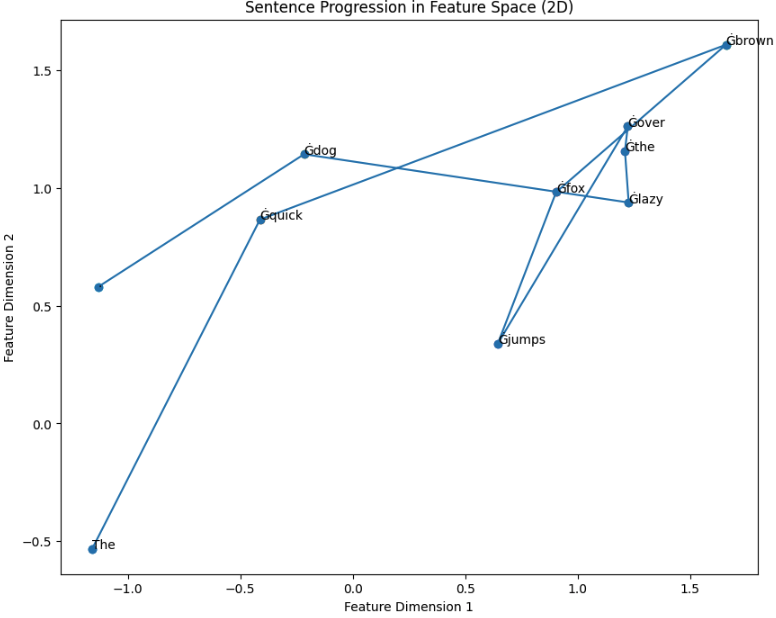
We can choose different dimensions from the hidden vector to get different angles of the data, which is why I use the PCA to standardise the view to the one with the most variance. This hopefully also gives the most information to the CNN. E.g. here's the same progression as above with different axes:
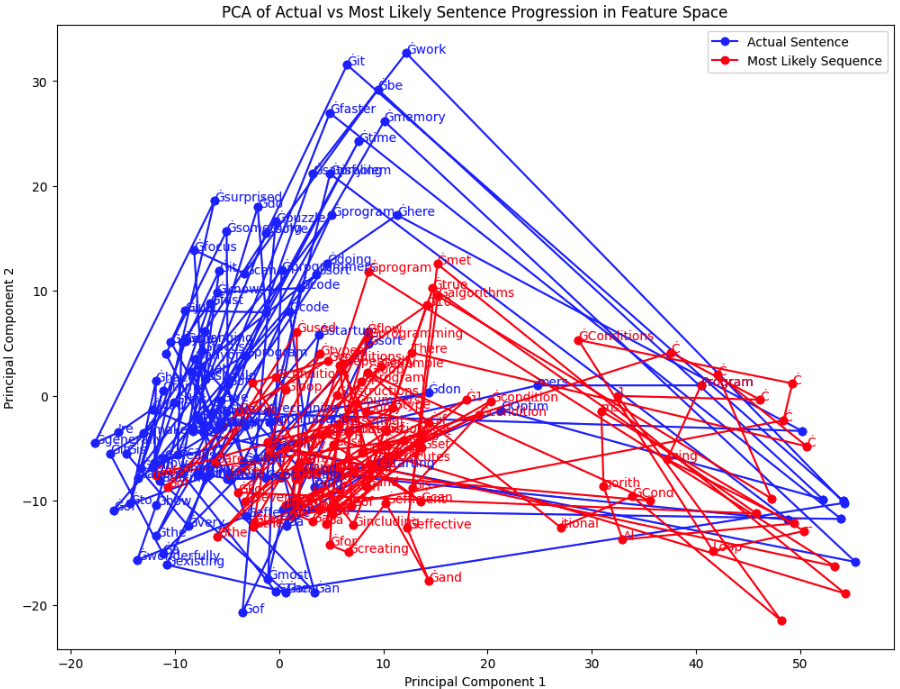
But are there variations in the text that are discernible? I think so. I've included both the text and the most likely sequence to make it clearer below.
Here's some text by PG and it's associated image:
Programmers will recognize what we're doing here. We're turning starting a startup into an optimization problem. And anyone who has tried optimizing code knows how wonderfully effective that sort of narrow focus can be. Optimizing code means taking an existing program and changing it to use less of something, usually time or memory. You don't have to think about what the program should do, just make it faster. For most programmers this is very satisfying work. The narrow focus makes it a sort of puzzle, and you're generally surprised how fast you can solve it.
Here's Anthony Bourdain:
It is about sodium-loaded pork fat, stinky triple-cream cheeses, the tender thymus glands and distended livers of young animals. It’s about danger—risking the dark, bacterial forces of beef, chicken, cheese, and shellfish. Your first two hundred and seven Wellfleet oysters may transport you to a state of rapture, but your two hundred and eighth may send you to bed with the sweats, chills, and vomits
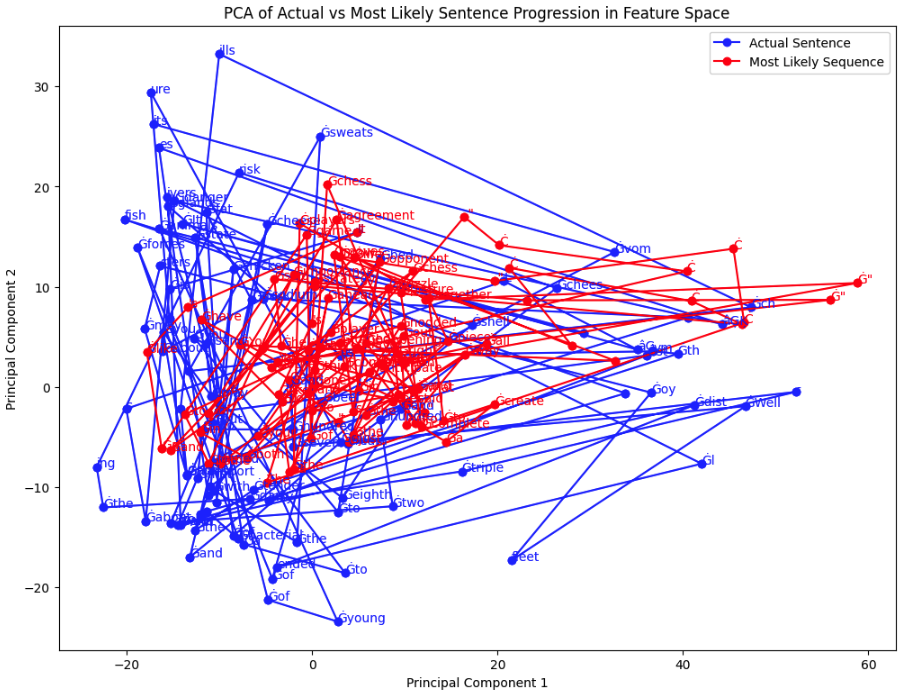
Here's Shakespeare:
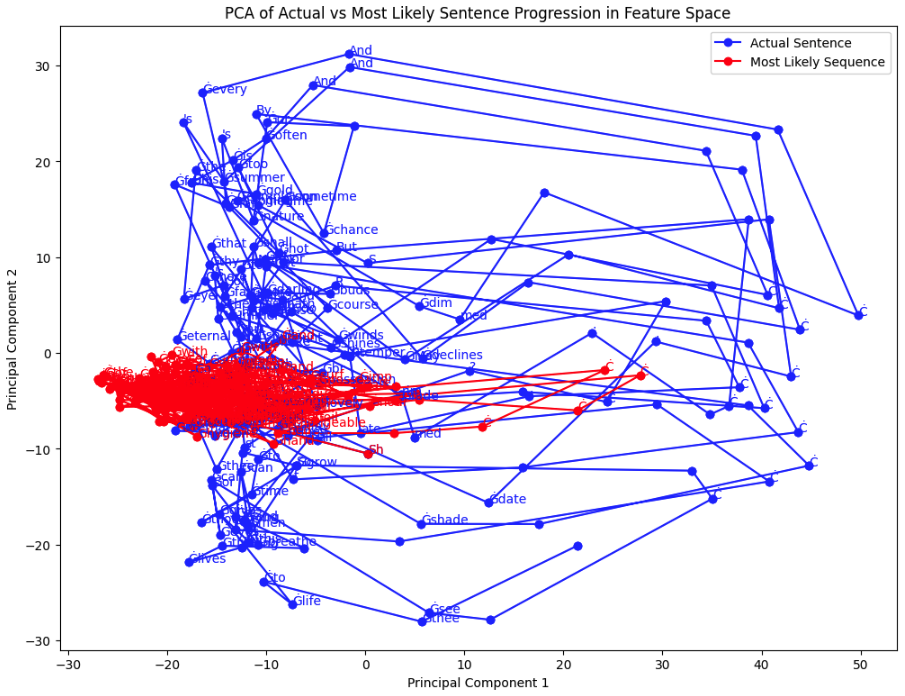
Shall I compare thee to a summer's day? Thou art more lovely and more temperate: Rough winds do shake the darling buds of May, And summer's lease hath all too short a date: Sometime too hot the eye of heaven shines, And often is his gold complexion dimmed, And every fair from fair sometime declines, By chance, or nature's changing course untrimmed: But thy eternal summer shall not fade, Nor lose possession of that fair thou ow'st, Nor shall death brag thou wand'rest in his shade, When in eternal lines to time thou grow'st, So long as men can breathe or eyes can see, So long lives this, and this gives life to thee.
We can already see some differences between the images. PG's seems to almost be hat shaped, without much traversal in the middle, more likely areas.
Bourdain's more ornate writing hops all over, with lots of stops in the middle.
And Shakespeare, with a lot of newlines and text very unlike what we use today, forms a large donut around the more likely text.
To generate the dataset, I took around 30,000 words of 5 writers:
- PG
- Homer
- Meditations
- Plato
- Shakespeare
Mainly chosen because of ease of internet availability.
I then selected random snippet of the text with sizes between 50 and a 1000 characters, and generated the graphs from them, excluding everything but the dots and lines. Here's an example:

There were 600 images per class. Finally, I trained a CNN on this data.
Results
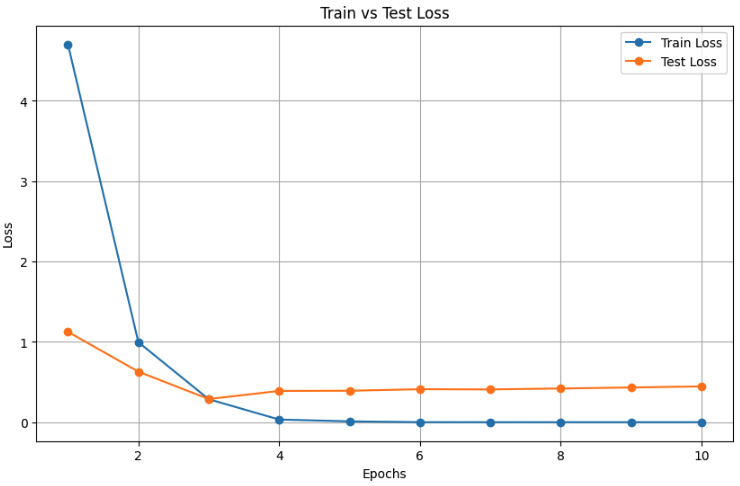
The losses from training for 10 epochs:
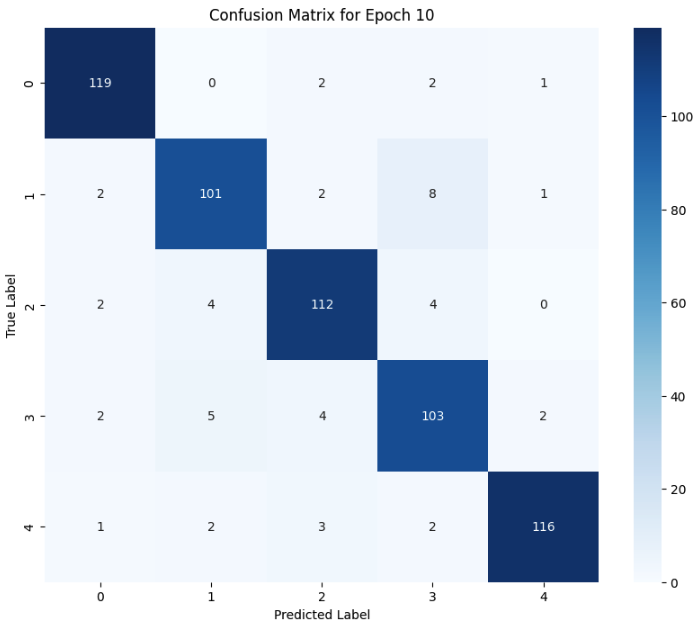
The confusion matrix:
And some stats:
- Accuracy: 0.9183333333333333
- Precision: 0.9187902357419933
- Recall: 0.9183333333333333
- F1 Score: 0.9184523469663879
Analysis/Questions
At first glance, it seem's pretty good, with an F1 score of 0.918. I'm skipping a lot of details you can see in the notebooks linked below, but even with just 100 images per class, it seemed to detect some differences.
Looks like it's a yes we can pick up on statistical features of progressions through LLM latent spaces to detect who wrote something. But while I definitely think there's something here, I'm pretty skeptical that it could be this good this fast.
- There’s a high chance the model might be detecting idiosyncrasies of the training data. For example, Shakespeare has a ton of newlines.
- In some sense, I'm training on the test set. The test set is drawn from exactly the same distribution as the training data, in the sense that the randomized snippets of text could overlap.
But arguably these idiosyncracies are also part of the style. If I saw Shakespeare’s writing without newlines, it’d be a lot harder to immediately guess it was him
Some questions:
Data
- Would accuracy improve or decrease with a standardized text length?
- How can I change the images to improve accuracy? Thinner lines? More colorful dots?
- Would the model improve if the images contained both the most likely text and the actual progression ?
- How sensitive is the model to newlines?
Architecture
- How does changing the CNN architecture affect performance? Would finetuning a model help?
- What happens if I simply run it over the vectors (not using a CNN) instead of turning it into an image first?
Misc
- What happens if I make a ‘signature’ image (a progression of all the text in the training data) by simply running it over a huge amount of text? How different will they look?
Is this valuable? I don’t necessarily know- I was just trying to validate a hunch. But it makes me wonder if we can compress the progression of any system somehow into latent space, and then use ML to categorise and quantify them.
Again, if you're doing research similar to this, or have any interesting things to share with me along these lines, please reach out! (twitter, email) Also I'm actively looking for 'research mentors', i.e. nothing too intense, just people who are willing to drop me a line of advice now and then for research related. If you are/know someone who can do this, I'd appreciate getting in touch!
Thanks for reading!
Sarv
Appendix
link to notebook (kinda messy)
My first (in retrospect dumb) experiment was - I turned the actual word probabilities and most likely word probabilities into a vector, and then found the angle. This didn’t seem to map to any useful quantity)
Then I thought about finding the probability of the word that came next in a sentence and subtract that from the probability of the most likely word. Then, sum up the differences. The idea being that this would capture the average deviation, and in what direction. But I realised that was very close to figuring out the surprisal, which in turn was similar to finding the perplexity. Which means I was finding out how ‘not robotic’ the text was. Interesting, but not our task.
I then thought of plotting the progression of text against the most likely text. First I did this per word.
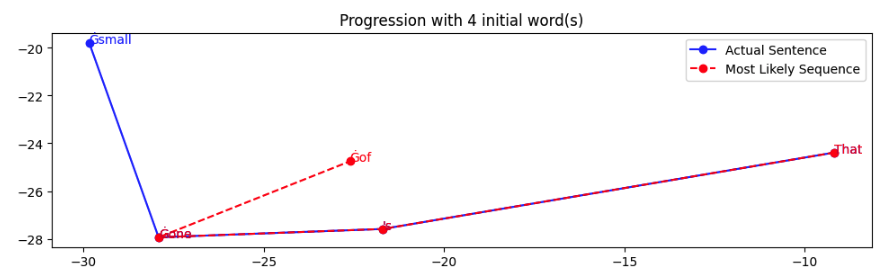
Then I did this per snippet of text, where I let the model generate the most likely text from the starting word, and then plotted that against where the words actually went. It’s after this that I did the method in the post above.